






TOC
Table of Contents
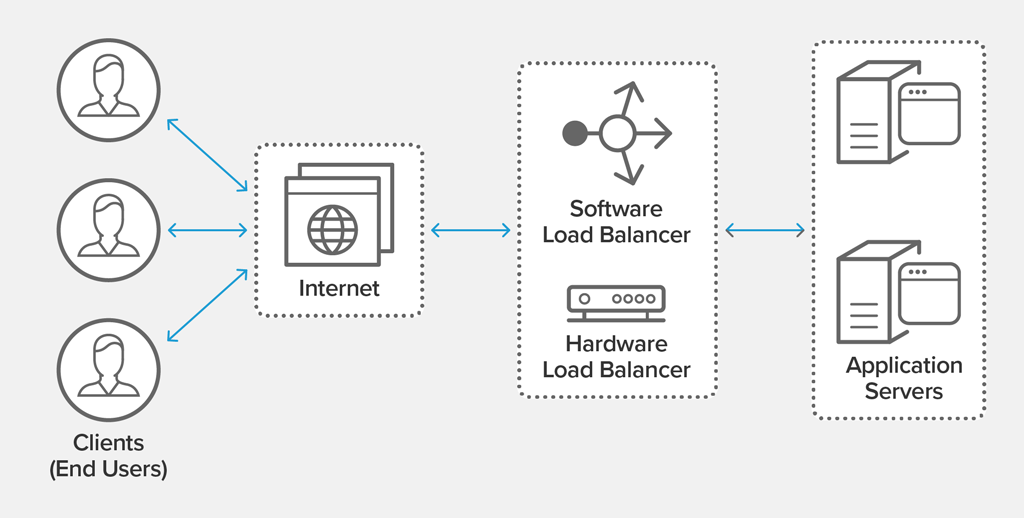
Overview
NGINX Open Source supports four load‑balancing methods.
- Round Robin
- Least Connections
- IP Hash
- Generic Hash
Round Robin
Requests are spread uniformly across the servers, taking into account server weights. This approach is used by default (there is no way to turn it off).
upstream backend {
# no load balancing method is specified for Round Robin
server backend1.example.com;
server backend2.example.com;
}Least Connections
A request is delivered to the server with the fewest active connections, again taking into account server weights.
upstream backend {
least_conn;
server backend1.example.com;
server backend2.example.com;
}IP Hash
The client IP address is used to determine which server a request is forwarded to. In this situation, the hash value is calculated using either the first three octets of the IPv4 address or the entire IPv6 address. Unless the server is unavailable, the approach ensures that requests from the same address are routed to the same server.
upstream backend {
ip_hash;
server backend1.example.com;
server backend2.example.com;
}If one of the servers has to be withdrawn from the loadbalancing cycle momentarily, it can be designated with the down option to keep the existing hashing of client IP addresses. Requests that this server was supposed to handle are automatically routed to the next server in the group.
upstream backend {
server backend1.example.com;
server backend2.example.com;
server backend3.example.com down;
}Generic Hash
A user-defined key, which might be a text string, variable, or a combination, determines which server a request is sent to. For instance, the key could be a URI or a coupled source IP address and port, as in this example.
upstream backend {
hash $request_uri consistent;
server backend1.example.com;
server backend2.example.com;
}The hash directive’s optional consistent parameter enables ketama consistent hash load balancing. Based on the user-defined hashed key value, requests are dispersed uniformly among all upstream servers. Only a few keys are remapped when an upstream server is added to or withdrawn from an upstream group, reducing cache misses in load-balancing cache servers or other applications that store state.
Note: NGINX Plus adds two more methods, but we don’t support them because they’re part of their enterprise package.
Leave a Reply
You must be logged in to post a comment.